
LLMs in Product Development: How to Prioritize Your Initiatives
/in Insights, Media ArticleIn issue 240 of CAD Magazine, Jean-Sebastien Gros – Partner in charge of Innovation – and Xavier Brucker – Managing Partner at Mews Labs, our Data Science & AI hub – explore the potential of generative AI for engineering.
Large Language Models (LLMs), a form of generative AI, have become ubiquitous in current discourse. Their seemingly limitless range of applications fuels engineers’ imagination across the entire value chain. For R&D teams in particular, this technology promises significant value creation.
Theoretically, R&D – and more specifically, product development engineering – appears to be a natural fit for this technology. It is, by design, a collaborative field that generates vast amounts of written knowledge, often fragmented and semi-structured. And if there’s one element that ties all these dispersed assets together, it is language — precisely the substrate on which LLMs thrive.
However, a “natural compatibility” does not automatically make a technology a business game changer. The dominant narrative, which insists on the urgency of boarding the AI train, often distracts from the essentials: starting with concrete operational needs, choosing the right technologies accordingly, and iterating. In other words: aim for industrialization, not flashy one-off proofs of concept.
This raises a core question: how can we assess whether LLMs are relevant for a given use case? What criteria should we apply to prioritize LLM deployments and build a roadmap of viable, scalable projects?

CRITERION #1: DATA TYPOLOGY AND STRUCTURE
LLMs are, first and foremost, data driven. Their output is only as good as the data they are fed. In this regard, the typology (and reliability) of available data becomes the defining factor for a use case’s feasibility. LLMs particularly excel at handling unstructured or semi-structured content. They are less relevant when applied to highly structured databases with clearly defined attributes – where a conventional search will likely yield faster, more reliable results.
Where LLMs shine is in mining disparate documentation (e.g. quality incident logs, project notes, technical standards) to surface relevant insights or identify analogous solutions to past issues — such as improving the reliability of a mechanical system.
CRITERION #2: STAKEHOLDER MATURITY AND ROLE ALIGNMENT
LLM relevance is not binary. In some contexts, their value is cross-cutting and general; in others, they support specific steps within a broader workflow. The user’s role, their familiarity with the topic, and their expectations regarding precision (see Criterion 4) are all critical variables.
The less specialized the user, the lower the performance threshold, and the higher the perceived value of the LLM.
Take requirement generation, for instance. Much of the challenge lies with downstream stakeholders in industrialization, who often identify and solve issues that ideally should be traced back as formal requirements during the design phase. However, writing such requirements is rarely part of their standard engineering reflexes — making it a weak link in the process. Given that these requirements typically emerge from loosely structured documents, LLMs could deliver significant support in bridging that gap.

CRITERION #3: ALIGNMENT BETWEEN GOALS AND LLM CAPABILITIES
While use cases should always be grounded in real needs, it is still essential to ensure that those needs align with what LLMs do best. Some goals — such as translation, summarization, or the generation of training or user documentation — are perfect candidates for rapid deployment with minimal tuning.
More advanced functions — such as consistency checks across technical specs — may require custom development, often involving hybrid architectures that combine LLMs with other AI or rule-based systems.
CRITERION #4: REQUIRED LEVEL OF ACCURACY
Closely tied to the previous point is the issue of expected precision. Generally, the more critical the task, the less suitable an out-of-the-box LLM becomes. These models excel in contexts where approximate synthesis is acceptable — such as training content or general awareness materials. But relying on them to generate maintenance documentation, where inaccuracies can have operational consequences, is far riskier.
In such cases, LLM usage must be accompanied by rigorous expert validation, the cost of which must be weighed against the added value.
CRITERION #5: LEVEL OF COMPLEXITY
Use case complexity is also a key factor — defined by the number and heterogeneity of steps involved, as well as the degree of process standardization. Designing a system model (which requires detailed definition of architectural elements and their interconnections) or building a verification & validation plan are examples of complex use cases. The higher the complexity, the more effort required — and the clearer the value must be to justify the investment.
Il conviendra alors d’accompagner l’utilisation du LLM d’un contrôle qualité rigoureux par un utilisateur expert… à mettre en balance, encore une fois, avec la valeur ajoutée du use case.
CONCLUSION
To meet these criteria, it quickly becomes clear that LLM adoption must be tailored. Beyond early “quick wins,” meaningful applications will demand dedicated engineering efforts — and they must be worth it.
Ultimately, the goal is not to label use cases as “LLM-compatible” or not, but to prioritize those in which value can be delivered quickly and sustainably. Scalability and return on investment should guide every decision — ensuring that generative AI serves as a driver of industrial transformation, not just a passing trend.
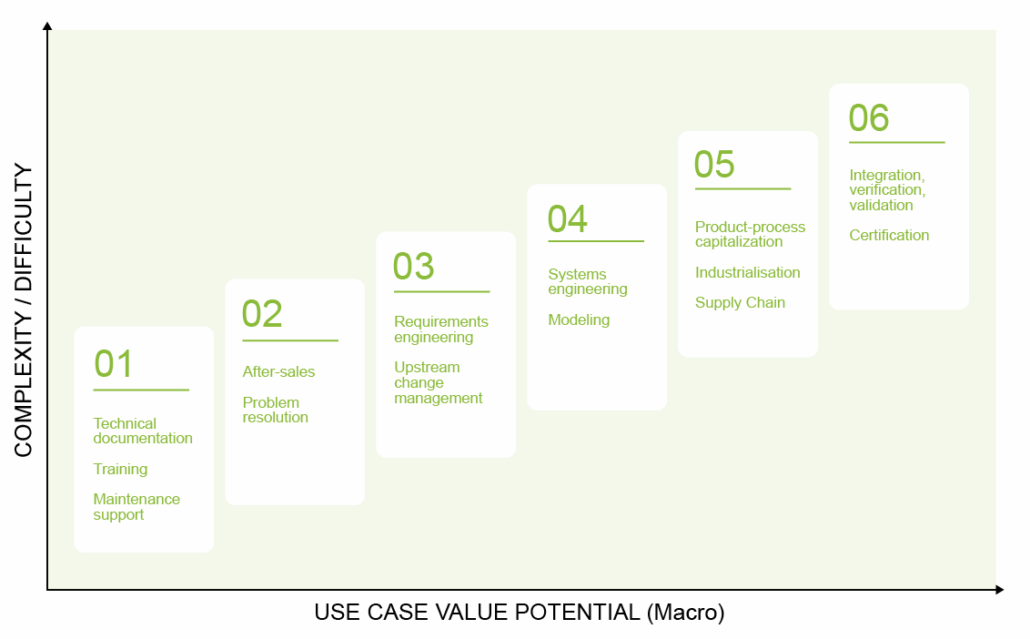
Schématisation du quick-win aux cas les plus complexes